Cost Optimization Strategies for AI Agents
Learn effective techniques to manage and reduce costs when deploying AI agents at scale
Understanding AI Agent Costs
Deploying AI agents can be expensive, particularly when using commercial large language models (LLMs) and other AI services. This guide will help you identify cost drivers and implement proven strategies to optimize your expenses without compromising quality.
Primary Cost Components
- API usage fees: Per-token charges for commercial LLM APIs
- Infrastructure costs: Compute resources, storage, and networking
- Bandwidth: Data transfer fees and networking costs
- Vector database usage: Storage and query costs for embedding databases
- Additional services: Image generation, speech recognition, etc.
Example Cost Breakdown
For a customer support AI agent handling 10,000 queries per day:
- LLM API costs: ~$30-50 per day (depending on model and query complexity)
- Vector database: ~$5-10 per day
- Infrastructure: ~$10-20 per day (depending on scaling needs)
- Monthly total: ~$1,500-2,400
LLM Token Optimization
Since many commercial LLMs charge by token count, optimizing token usage is one of the most effective ways to reduce costs.
Prompt Engineering for Cost Efficiency
- Concise prompts: Reduce unnecessary context in system and user prompts
- Context windowing: Only include relevant portions of documents
- Dynamic temperature: Use higher temperatures for creative tasks, lower for factual ones
- Task-specific models: Use smaller, specialized models when appropriate
# Example: Dynamic temperature setting based on task type
def get_optimal_temperature(task_type):
"""Return the optimal temperature setting based on task type."""
temp_settings = {
"creative_writing": 0.7,
"code_generation": 0.2,
"factual_qa": 0.0,
"summarization": 0.3,
"classification": 0.0,
"default": 0.5
}
return temp_settings.get(task_type, temp_settings["default"])
def query_llm(prompt, task_type):
"""Query LLM with optimized settings for the specific task."""
temperature = get_optimal_temperature(task_type)
# Use the appropriate model based on task complexity
if task_type in ["code_generation", "creative_writing"]:
model = "gpt-4" # More capable but expensive
else:
model = "gpt-3.5-turbo" # Less expensive
return openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)Context Management Techniques
Efficiently managing context is crucial for reducing token usage:
- Message summarization: Condense chat history instead of sending full transcripts
- Key information extraction: Only retain essential information from previous interactions
- Semantic chunking: Break documents into meaningful chunks before retrieval
Message Summarization Example
# Example: Summarizing conversation history to reduce token count
def summarize_conversation(conversation_history):
"""Summarize conversation history to reduce token count."""
if len(conversation_history) <= 2:
return conversation_history # Not enough history to summarize
# Extract only the last two messages for immediate context
recent_messages = conversation_history[-2:]
# If the history is longer, summarize everything before that
if len(conversation_history) > 2:
# Create a summary prompt
summary_prompt = "Summarize the following conversation concisely, " \
"focusing only on key points and user needs:\n\n"
for msg in conversation_history[:-2]:
summary_prompt += f"{msg['role']}: {msg['content']}\n"
# Get summary from a cheaper, smaller model
summary_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": summary_prompt}],
temperature=0.3,
max_tokens=100 # Limit summary length
)
summary = summary_response.choices[0].message.content
# Return the summary as system message + recent messages
return [
{"role": "system", "content": f"Previous conversation summary: {summary}"},
*recent_messages
]
return conversation_historyCaching and Memoization
Implementing caching strategies can significantly reduce API calls for common queries and scenarios.
Response Caching
Store responses to common queries to avoid redundant API calls:
# Example: Advanced caching system with semantic similarity
import redis
import hashlib
import numpy as np
from sentence_transformers import SentenceTransformer
class SemanticCache:
def __init__(self, redis_url, similarity_threshold=0.92, ttl=86400):
self.redis = redis.from_url(redis_url)
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
self.similarity_threshold = similarity_threshold
self.ttl = ttl # Cache TTL in seconds (default: 24 hours)
def _get_embedding(self, text):
"""Get embedding for a text string."""
return self.encoder.encode(text)
def _compute_similarity(self, embedding1, embedding2):
"""Compute cosine similarity between embeddings."""
return np.dot(embedding1, embedding2) / (np.linalg.norm(embedding1) * np.linalg.norm(embedding2))
def get_from_cache(self, query):
"""Get response from cache if semantically similar query exists."""
query_embedding = self._get_embedding(query)
# Check exact match first (faster)
query_hash = hashlib.md5(query.encode()).hexdigest()
exact_match = self.redis.hgetall(f"exact:{query_hash}")
if exact_match:
return exact_match.get(b'response').decode()
# Look for semantic matches
cache_keys = self.redis.keys("semantic:*")
for key in cache_keys:
cached_embedding = np.frombuffer(self.redis.hget(key, 'embedding'), dtype=np.float32)
similarity = self._compute_similarity(query_embedding, cached_embedding)
if similarity >= self.similarity_threshold:
return self.redis.hget(key, 'response').decode()
return None
def add_to_cache(self, query, response):
"""Add query-response pair to cache."""
# Add exact match
query_hash = hashlib.md5(query.encode()).hexdigest()
self.redis.hset(f"exact:{query_hash}", mapping={'response': response})
self.redis.expire(f"exact:{query_hash}", self.ttl)
# Add semantic match
query_embedding = self._get_embedding(query)
semantic_key = f"semantic:{query_hash}"
self.redis.hset(semantic_key, mapping={
'query': query,
'response': response,
'embedding': query_embedding.tobytes()
})
self.redis.expire(semantic_key, self.ttl)
def query_with_cache(self, query_function, query):
"""Query with caching wrapper."""
cached_response = self.get_from_cache(query)
if cached_response:
return cached_response
# Call the actual query function if not in cache
response = query_function(query)
# Add to cache
self.add_to_cache(query, response)
return responseTiered Caching Strategies
Implement multi-level caching for optimal performance and cost savings:
- In-memory cache: For highest frequency queries with minimal latency
- Redis/Memcached: For medium frequency queries across multiple instances
- Database cache: For longer-term storage of common queries
Cache Effectiveness
For a production AI assistant with 1 million queries per month:
- Without caching: ~$10,000 in API costs
- With basic caching (30% hit rate): ~$7,000 in API costs
- With advanced semantic caching (50% hit rate): ~$5,000 in API costs
Model Selection and Cascading
Not every query requires your most powerful and expensive model. Implementing model cascading can significantly reduce costs.
Model Cascading Approach
Start with smaller, cheaper models and only escalate to more expensive ones when necessary:
# Example: Cascading model selection based on task complexity
def cascading_query(query, system_prompt="You are a helpful assistant"):
"""Use cascading models to optimize for cost while maintaining quality."""
# Step 1: Classify the query complexity
classification_prompt = f"""
Classify the following query as SIMPLE, MEDIUM, or COMPLEX:
- SIMPLE: Basic factual questions, simple tasks, routine operations
- MEDIUM: Multi-step tasks, explanations requiring domain knowledge
- COMPLEX: Tasks requiring reasoning, creativity, or specialized expertise
Query: {query}
Answer with just one word: SIMPLE, MEDIUM, or COMPLEX.
"""
classification = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # Use cheaper model for classification
messages=[{"role": "user", "content": classification_prompt}],
temperature=0,
max_tokens=10
).choices[0].message.content.strip()
# Step 2: Select appropriate model based on complexity
if "SIMPLE" in classification:
model = "gpt-3.5-turbo"
max_tokens = 500
elif "MEDIUM" in classification:
model = "gpt-3.5-turbo-16k" # More context but still cost-effective
max_tokens = 1000
else: # COMPLEX
model = "gpt-4" # Most capable but expensive
max_tokens = 2000
# Step 3: Process with selected model
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
temperature=0.7,
max_tokens=max_tokens
)
return {
"response": response.choices[0].message.content,
"model_used": model,
"complexity": classification
}Local Model Integration
For certain tasks, local open-source models can provide significant cost savings:
- Embedding models: Use local models for embeddings and similarity search
- Classification tasks: Fine-tuned smaller models can handle specific classifications
- Hybrid approaches: Combine local models with cloud APIs for optimal performance
Example: Local Embedding Model
# Example: Using local embedding model instead of OpenAI's
from sentence_transformers import SentenceTransformer
# Load model once at startup
local_embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
def get_embeddings(texts):
"""Generate embeddings using local model instead of API calls."""
return local_embedding_model.encode(texts)
# Usage for vector search
document_embeddings = get_embeddings(documents)
query_embedding = get_embeddings([user_query])[0]
# Find similar documents
similarities = document_embeddings @ query_embedding
top_doc_indices = np.argsort(similarities)[-3:][::-1] # Top 3 matchesInfrastructure Optimization
Beyond API costs, infrastructure expenses can be significant. Here are strategies to optimize your cloud and hardware costs.
Cloud Resource Management
- Auto-scaling: Scale resources based on actual demand patterns
- Spot instances: Use discounted compute resources for non-critical workloads
- Reserved instances: Pre-purchase capacity for predictable workloads
- Right-sizing: Match instance types to actual workload requirements
# Example: Terraform configuration for auto-scaling with AWS
{
"resource": {
"aws_appautoscaling_target": {
"ecs_target": {
"service_namespace": "ecs",
"resource_id": "service/ai-agent-cluster/ai-agent-service",
"scalable_dimension": "ecs:service:DesiredCount",
"min_capacity": 2,
"max_capacity": 10
}
},
"aws_appautoscaling_policy": {
"scale_up": {
"name": "scale_up",
"service_namespace": "ecs",
"resource_id": "service/ai-agent-cluster/ai-agent-service",
"scalable_dimension": "ecs:service:DesiredCount",
"step_scaling_policy_configuration": {
"adjustment_type": "ChangeInCapacity",
"cooldown": 60,
"metric_aggregation_type": "Average",
"step_adjustment": {
"metric_interval_lower_bound": 0,
"scaling_adjustment": 1
}
}
},
"scale_down": {
"name": "scale_down",
"service_namespace": "ecs",
"resource_id": "service/ai-agent-cluster/ai-agent-service",
"scalable_dimension": "ecs:service:DesiredCount",
"step_scaling_policy_configuration": {
"adjustment_type": "ChangeInCapacity",
"cooldown": 60,
"metric_aggregation_type": "Average",
"step_adjustment": {
"metric_interval_upper_bound": 0,
"scaling_adjustment": -1
}
}
}
}
}
}Serverless vs. Container Trade-offs
Choose the right deployment approach based on your usage patterns:
- Serverless: Best for sporadic usage with cost-effective scaling to zero
- Containers: More economical for consistent, predictable workloads
Deployment Cost Comparison
| Deployment Type | Low Usage (1K queries/day) |
Medium Usage (10K queries/day) |
High Usage (100K queries/day) |
|---|---|---|---|
| Serverless | $40-60/month | $200-300/month | $3,000-4,000/month |
| Containers (K8s) | $150-250/month | $200-350/month | $1,500-2,500/month |
| VMs | $100-200/month | $250-400/month | $2,000-3,000/month |
Note: These are approximate costs that can vary based on cloud provider, region, and specific implementation details.
Batch Processing and Asynchronous Patterns
Batch processing requests can lead to significant cost reductions and better resource utilization.
Batch Processing Implementation
# Example: Batch processing for LLM requests
import asyncio
import time
from typing import List, Dict
import openai
class BatchProcessor:
def __init__(self, max_batch_size=20, max_wait_time=2.0):
self.queue = []
self.max_batch_size = max_batch_size
self.max_wait_time = max_wait_time
self.processing = False
self.last_item_time = None
async def add_item(self, prompt: str) -> str:
"""Add item to queue and wait for result."""
# Create future to track this specific request
future = asyncio.Future()
# Add to queue
self.queue.append((prompt, future))
# Update timestamp of last item
self.last_item_time = time.time()
# Start processing if not already running
if not self.processing:
asyncio.create_task(self._process_queue())
# Wait for result
return await future
async def _process_queue(self):
"""Process items in queue as batches."""
self.processing = True
while self.queue:
# Determine if we should process now
should_process = len(self.queue) >= self.max_batch_size
# If queue isn't full, check if we've waited long enough
if not should_process and self.last_item_time:
time_since_last_item = time.time() - self.last_item_time
should_process = time_since_last_item >= self.max_wait_time
if should_process:
# Get batch from queue (up to max size)
batch = self.queue[:self.max_batch_size]
self.queue = self.queue[self.max_batch_size:]
# Process batch
prompts = [item[0] for item in batch]
try:
results = await self._batch_call_llm(prompts)
# Resolve all futures with their results
for (_, future), result in zip(batch, results):
future.set_result(result)
except Exception as e:
# Set exception for all futures in batch
for _, future in batch:
future.set_exception(e)
else:
# Wait a bit before checking again
await asyncio.sleep(0.1)
# Queue is empty
self.processing = False
async def _batch_call_llm(self, prompts: List[str]) -> List[str]:
"""Make batch API call to LLM."""
# Create batch request to OpenAI
responses = []
# Process in parallel using asyncio
async def process_single(prompt):
response = await openai.ChatCompletion.acreate(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
return response.choices[0].message.content
# Process all prompts in parallel
tasks = [process_single(prompt) for prompt in prompts]
responses = await asyncio.gather(*tasks)
return responses
# Usage example
async def main():
processor = BatchProcessor(max_batch_size=10, max_wait_time=1.0)
# Simulate multiple concurrent requests
tasks = []
for i in range(25):
query = f"Tell me about topic {i}"
tasks.append(processor.add_item(query))
responses = await asyncio.gather(*tasks)
# Process responses
for i, response in enumerate(responses):
print(f"Response {i}: {response[:50]}...")Asynchronous Processing Patterns
Implement asynchronous patterns for non-time-sensitive tasks:
- Job queues: Queue requests for processing during off-peak times
- Webhooks: Notify clients when long-running tasks complete
- Pre-computation: Process predictable queries ahead of time
Cost Monitoring and Budgeting
Establish robust monitoring and alerting systems to track expenses and prevent unexpected costs.
Key Monitoring Metrics
- API calls per minute/hour/day: Track usage patterns and anomalies
- Token consumption: Monitor input and output tokens
- Cost per query: Track the average and outlier costs
- Cache hit rate: Measure cache effectiveness
- Model distribution: Track usage across different models
Cost Dashboard Example
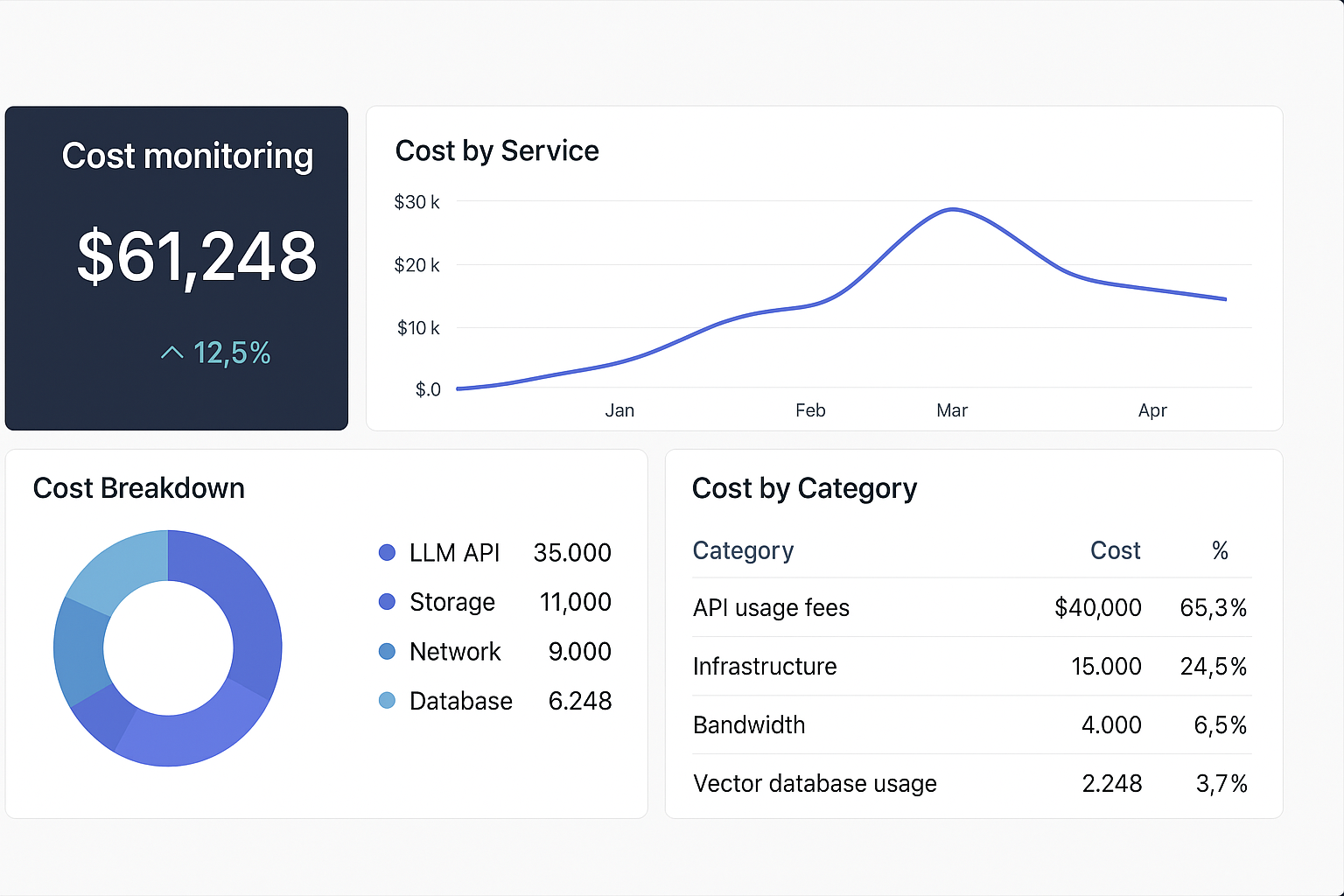
A comprehensive cost dashboard should track API usage, model distribution, and historical trends.
Budget Alerts and Throttling
Implement automatic alerts and controls to prevent cost overruns:
# Example: Budget control system for API usage
class BudgetController:
def __init__(self, daily_budget=100.0, alert_threshold=0.8):
self.daily_budget = daily_budget
self.alert_threshold = alert_threshold
self.current_spend = 0.0
self.last_reset = datetime.now().date()
self.alerted = False
self.lock = asyncio.Lock()
async def reset_if_needed(self):
"""Reset counters if it's a new day."""
today = datetime.now().date()
if today > self.last_reset:
async with self.lock:
self.current_spend = 0.0
self.last_reset = today
self.alerted = False
async def check_budget(self, estimated_cost):
"""Check if operation fits within budget."""
await self.reset_if_needed()
async with self.lock:
# Check if we would exceed budget
if self.current_spend + estimated_cost > self.daily_budget:
return False
# Check if we need to send an alert
if not self.alerted and self.current_spend >= self.daily_budget * self.alert_threshold:
self.alerted = True
await self.send_alert()
return True
async def record_spend(self, actual_cost):
"""Record actual cost of operation."""
async with self.lock:
self.current_spend += actual_cost
async def send_alert(self):
"""Send alert when approaching budget limit."""
# Send email, Slack notification, etc.
message = f"ALERT: AI API usage has reached {self.alert_threshold*100}% " \
f"of daily budget (${self.current_spend:.2f} / ${self.daily_budget:.2f})"
# Example: Send to Slack
# await send_to_slack(message)
print(message) # For demo purposes
# Usage example
async def query_with_budget_control(query, budget_controller):
# Estimate cost based on token count
input_tokens = len(query.split())
estimated_output_tokens = input_tokens * 2 # Rough estimate
estimated_cost = (input_tokens * 0.001 + estimated_output_tokens * 0.002) / 1000
# Check budget before proceeding
if not await budget_controller.check_budget(estimated_cost):
return "Sorry, daily API budget limit reached. Please try again tomorrow."
try:
# Make the actual API call
response = await openai.ChatCompletion.acreate(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": query}],
temperature=0.7
)
# Record actual spend
actual_input_tokens = response.usage.prompt_tokens
actual_output_tokens = response.usage.completion_tokens
actual_cost = (actual_input_tokens * 0.001 + actual_output_tokens * 0.002) / 1000
await budget_controller.record_spend(actual_cost)
return response.choices[0].message.content
except Exception as e:
# Handle error
print(f"Error in API call: {e}")
return f"An error occurred: {str(e)}"Optimization for Vector Databases
Vector databases used for retrieval-augmented generation (RAG) can be a significant cost driver. Here are strategies to optimize these costs.
Vector Database Cost Factors
- Storage costs: Cost of storing embeddings and metadata
- Query costs: Cost per vector similarity search
- Indexing costs: Computational expenses for building and maintaining indexes
- Data transfer: Costs for moving data in and out of the database
Vector Database Optimization Techniques
# Example: Optimized vector database configuration
from pymilvus import connections, utility
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
def optimize_vector_collection():
"""Create an optimized vector collection with balanced performance and cost."""
# Connect to Milvus
connections.connect("default", host="localhost", port="19530")
# Define optimized collection schema
fields = [
# Use smaller dimensions for embeddings when possible
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384), # Using smaller dimensions
FieldSchema(name="metadata", dtype=DataType.JSON)
]
schema = CollectionSchema(fields)
# Create collection with optimized settings
collection = Collection(name="optimized_docs", schema=schema)
# Create IVF_FLAT index (good balance between search speed and memory usage)
index_params = {
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024} # Adjust based on dataset size
}
collection.create_index("embedding", index_params)
# Load collection (keep loaded only when needed)
collection.load()
# Configure caching behavior for cost efficiency
utility.set_cache_config({"enable_cpu_cache": True, "cache_size": "4GB"})
return collection
def cost_efficient_search(collection, query_vector, top_k=3):
"""Perform cost-efficient vector search."""
# Use smaller top_k to reduce computation
search_params = {
"metric_type": "L2",
"params": {"nprobe": 16} # Lower nprobe reduces computation cost but may affect recall
}
results = collection.search(
data=[query_vector],
anns_field="embedding",
param=search_params,
limit=top_k,
expr=None
)
return resultsVector Database Cost Comparison
| Optimization Technique | Cost Impact | Performance Impact |
|---|---|---|
| Dimension Reduction (768 to 384) | -40% storage cost | -5% accuracy |
| Optimized Index Parameters | -25% compute cost | +10ms latency |
| Selective Loading/Unloading | -30% memory cost | +200ms initial query |
Real-world Case Studies
Learn from real-world implementations of cost optimization strategies in AI agent deployments.
E-commerce Assistant: 70% Cost Reduction
Case Study: Online Retailer
An e-commerce platform deployed an AI shopping assistant handling 50,000 customer interactions daily. Initial costs were approximately $15,000/month.
Implemented optimizations:
- Created a tiered model approach using GPT-3.5 Turbo for 85% of queries and GPT-4 only for complex cases
- Implemented semantic caching with a 42% hit rate
- Reduced prompt sizes through careful engineering and context summarization
- Used vector database dimension reduction and query optimization
Results:
- Reduced monthly costs to $4,500 (70% reduction)
- Maintained 96% of original customer satisfaction scores
- Reduced average response time by 18%
Enterprise Knowledge Base: 65% Cost Reduction
Case Study: Corporate Knowledge Assistant
A global consulting firm deployed an AI knowledge assistant to provide employees with instant access to company resources, handling approximately 30,000 queries per month.
Implemented optimizations:
- Cached frequent queries and implemented semantic similarity search
- Pre-computed embeddings for all documents in batch processing
- Implemented asynchronous processing for non-urgent requests
- Used serverless architecture with auto-scaling for cost efficiency
Results:
- Reduced monthly API costs from $12,000 to $4,200
- Decreased infrastructure costs by 60%
- Improved average response time from 4.2s to 1.8s
Emerging Cost Optimization Techniques
Keep an eye on these cutting-edge approaches to further reduce AI agent operating costs.
Quantization and Model Distillation
Newer techniques to reduce model size while preserving performance:
- Quantization: Reducing parameter precision from 32-bit to 8-bit or 4-bit
- Model distillation: Training smaller models to mimic larger models
- Pruning: Removing redundant parameters from models
Fine-tuning with Synthetic Data
Create custom-tuned smaller models that excel at specific tasks:
- Generate synthetic training data from larger models
- Fine-tune smaller models on task-specific data
- Deploy specialized smaller models at a fraction of the cost
Open-Source Model Cost Savings
Recent benchmark of a fine-tuned 7B parameter model against commercial APIs:
- Commercial API cost: ~$0.02 per 1K tokens
- Self-hosted 7B model: ~$0.0015 per 1K tokens
- Potential savings: >90% for high-volume applications
Cost Optimization Checklist
Use this checklist to ensure you've implemented key cost optimization strategies for your AI agent deployment: